boardom buster - my boardgame recommendation system
Boardom Buster
i present to you my most recent project Boardom Buster (boredom, get it? and buster because board games are super cool :D)
context
if you know me or have seen my small anti-resume, you probably know i'm a huge board game lover. i love playing them, i love how they look, i love how they bring people together. hell, i even love how fresh they smell when you rip them open for the first time! when looking for a new game, most people (myself included) usually do one of two things:
- check out content from well-known board game creators, watch playthroughs and read feedback.
- browse a website like board game geek (BGG), which is basically the bible of board games. if a game exists, it's there.
but here's the problem: there are literally thousands of games out there. how do you choose a good one? sure, you can check the trending games, look at someone's tier list on a forum, or find a game you like and search for something similar. but that’s where it gets tricky. how do you find a game you’ll actually enjoy, while also making sure it’s a solid game and not just similar in some vague way?
i want a good game. i want a similar game. maybe you love party games, maybe you love ending your night fighting with your friends because you kept moving the robber to their best tile, maybe you’re into wargames and want to conquer the world. whatever you’re into, you should be able to find a game you’ll actually enjoy. everyone likes tacos, but no one likes a bad taco. you get me?
and that’s where Boardom Buster comes in. my goal is to build something that doesn’t just suggest similar games but recommends ones you’ll actually enjoy based on your past experiences.
so, without further ado, let’s get into it!
idea
the idea is pretty simple. we needed to:
- get board games data – this is where BGG comes in handy. BGG has an API with all the info we need.
- process the data – perform (E)TL; clean the data, apply feature engineering and get it ready to use.
- cluster the games – use a learning algorithm to find similar games.
- get user input – ask the user for a game they would like to find similar recommendations.
- recommend a game – apply some conditions and weightings to ensure we’re not just suggesting a similar game, but a good one. if two games are equally close, we pick the better one. if a game is slightly farther but significantly better, we might recommend that instead.
implementation
get data from board games
i used what most people would: async requests. however, we quickly ran into a problem -- BGG’s API has pretty strict rate limits. to work around this, i benchmarked different configurations and landed on an approach inspired by gradient descent.
we optimize four key parameters:
- batch size – the number of async requests sent at once.
- chunk size – the size of each individual request batch.
- sleep time – how long we pause between request batches to avoid overloading the API.
- retry delay – how long we wait before retrying after hitting a rate limit.
process the data – (E)TL, cleaning and feature engineering
for this step, i chose to use polars. it’s the hot thing right now, and while the dataset size might not strictly justify it over pandas, i wanted to learn and experiment with it.
some of the feature engineering steps i applied:
- cleaned descriptions – stripped out html and unnecessary formatting.
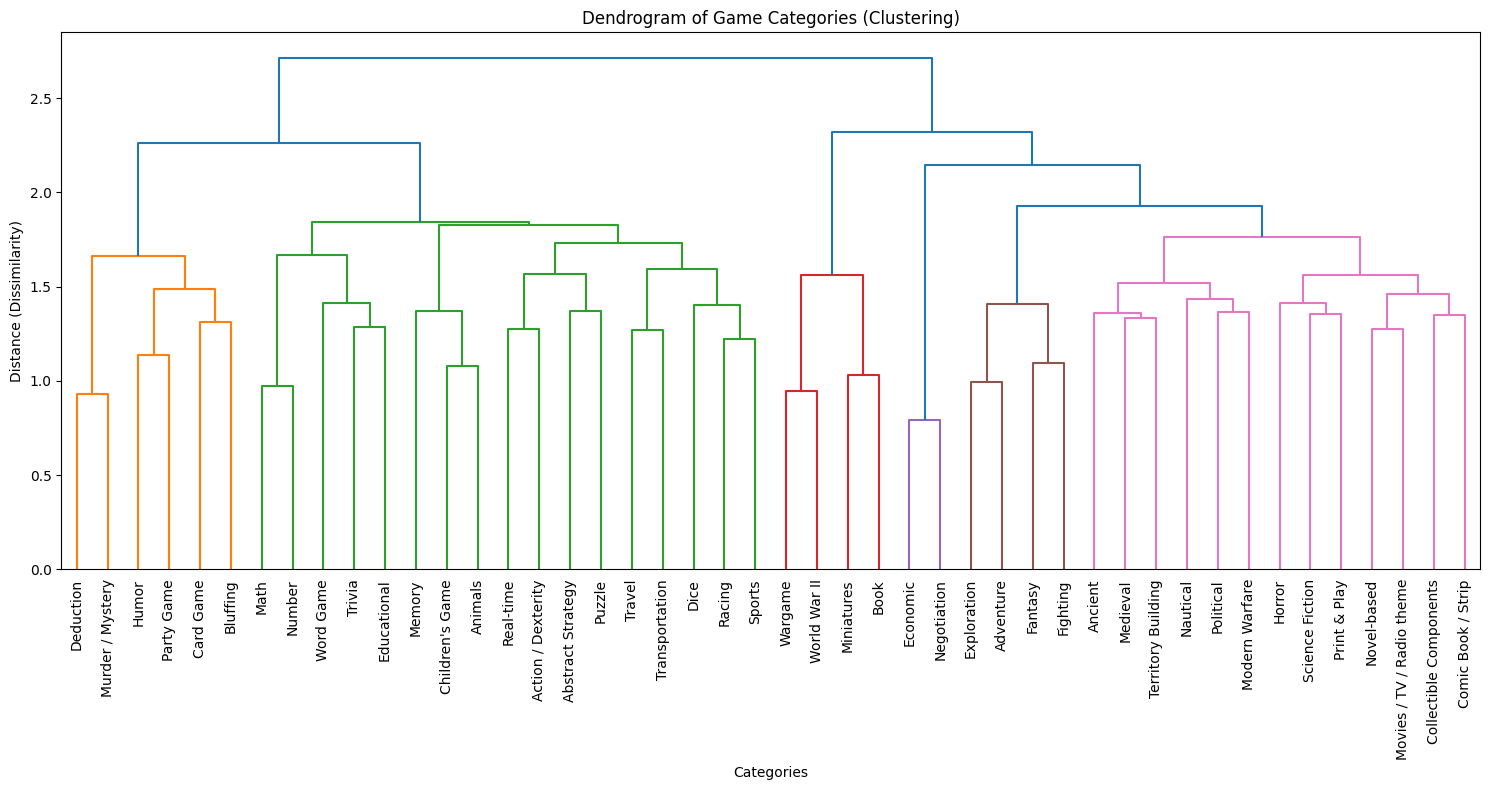
- grouped categories – grouped categories and mechanics based on how similar they were.
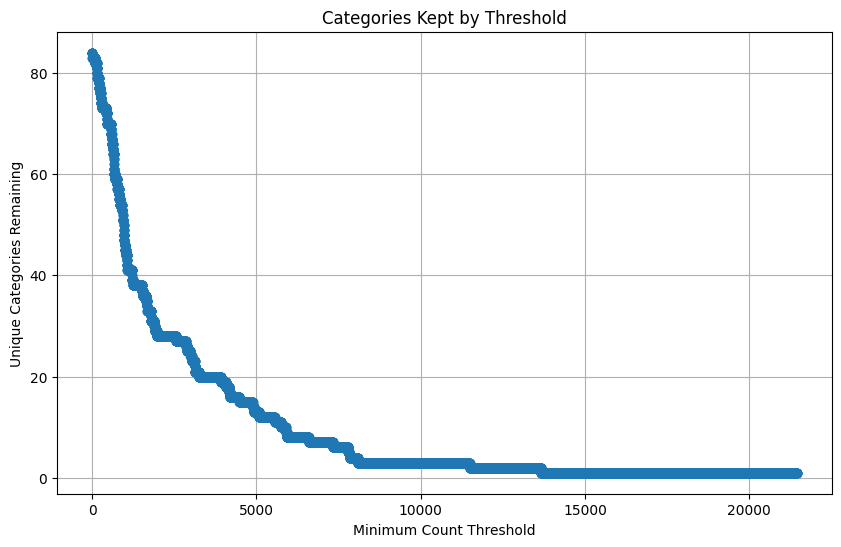
- eliminated non-meaningful entities based on thresholds – for example, i don't want to recommend a game with only one review, or consider categories that don't appear very often.
- one-hot encoded multiple columns – for example: if a game is meant for 4-6 people, i encode those values, the bigger the intersection between games, the more similar they are.
- clipped values – clipped outliers like playing time.
- popularity score – created a popularity score based on how many people own, want, or wish-list the game.
model
for the model i used the classic KNN (k-nearest neighbors). since we did a lot of one-hot encoding, euclidean distance wouldn't be very effective. instead, i used cosine distance to measure how similar the "profile" of two games is.
the secret sauce: re-ranking
finding similar games is step one, but finding good similar games is step two. i built a ReRanker that calculates a final score based on a weighted system:
- similarity score (cosine similarity)
- difficulty similarity (complexity match)
- playing time similarity (time match)
- bayesian rating (quality check)
- popularity (crowd favorite boost)
i also added a family deduplication step to ensure variety in the results.
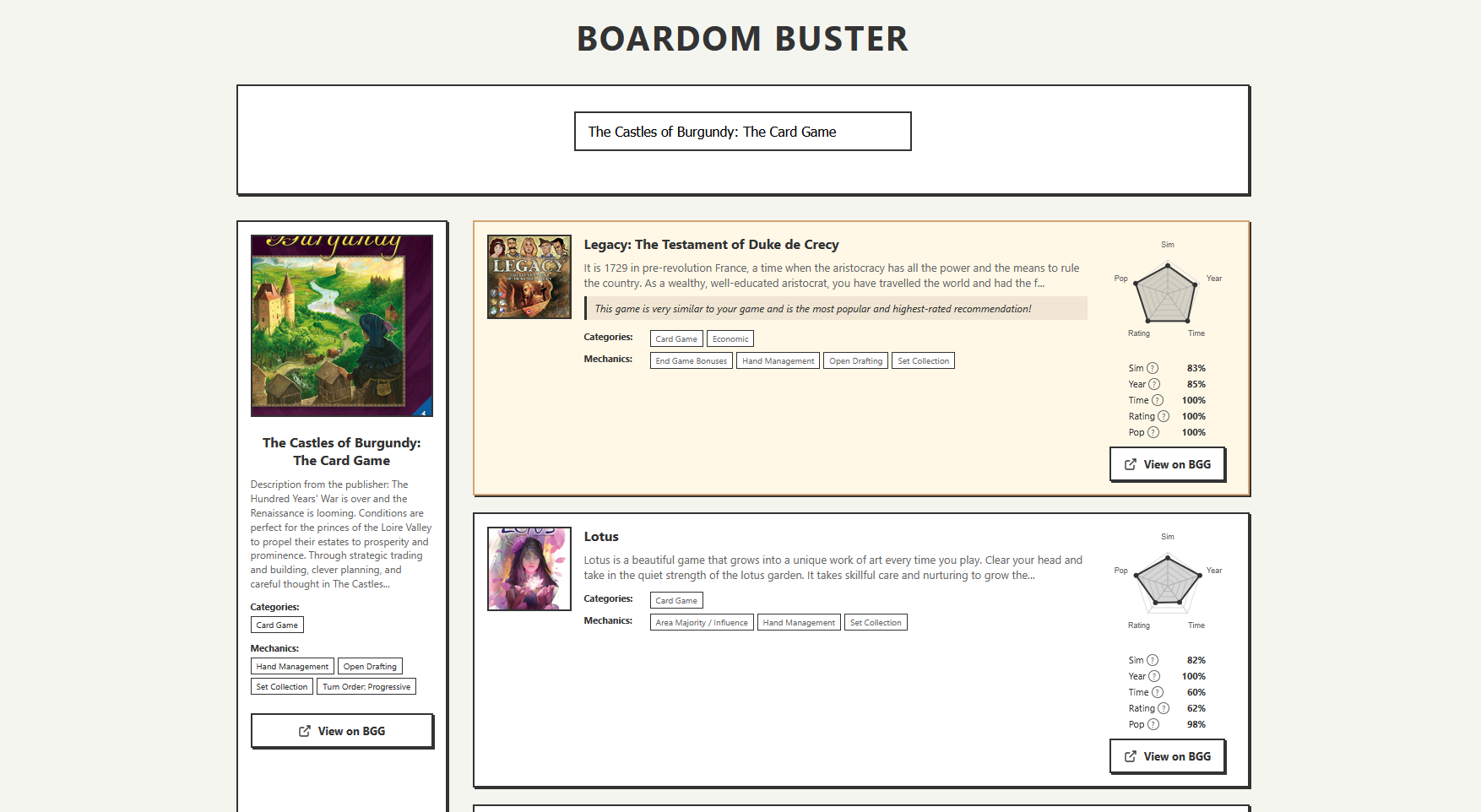
results
to make the recommendations more "human" i added a comment generator. now, the app doesn't just give you a list; it tells you why a game is there.
user journey
1. main page
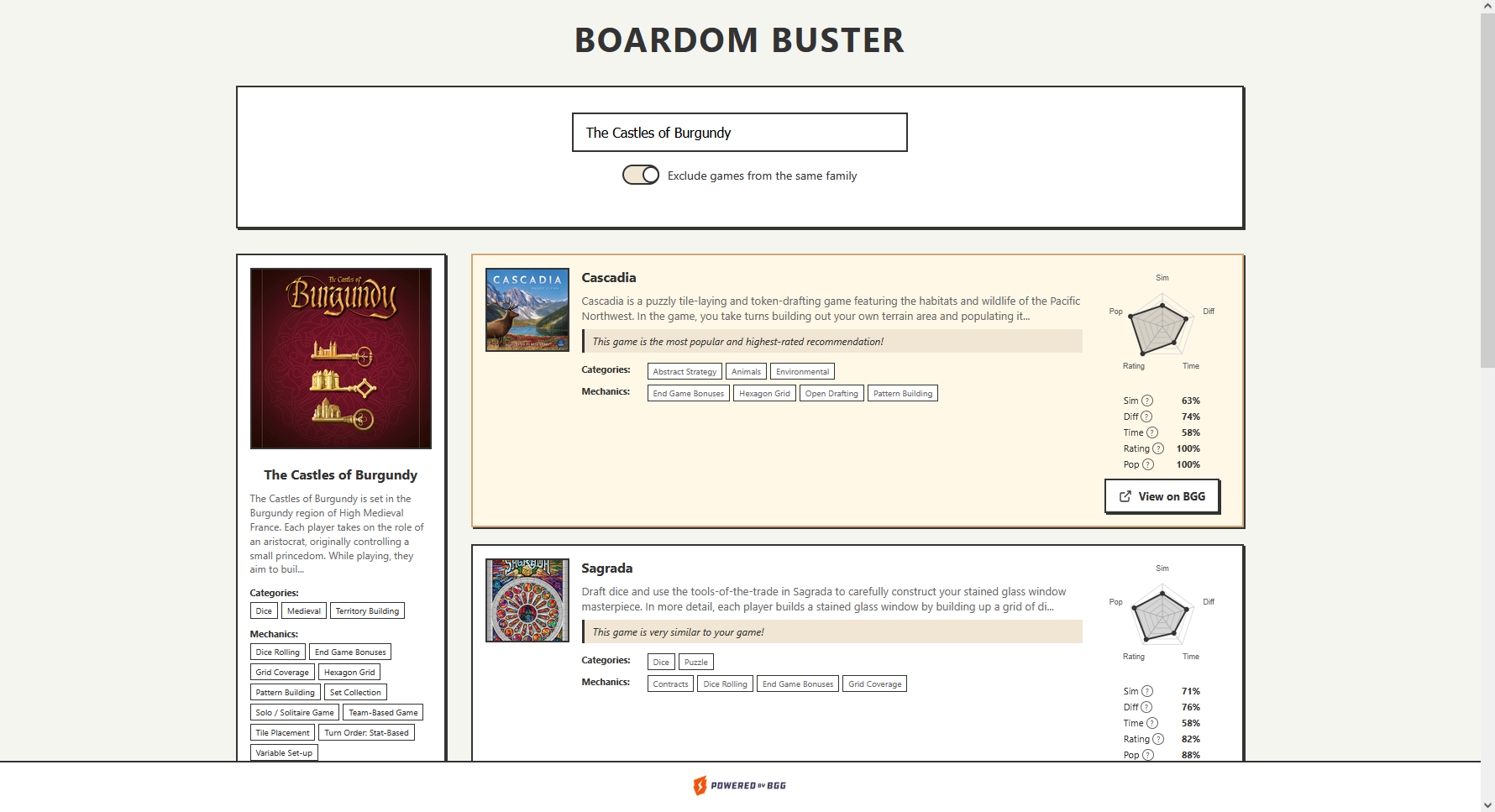
2. choosing a game
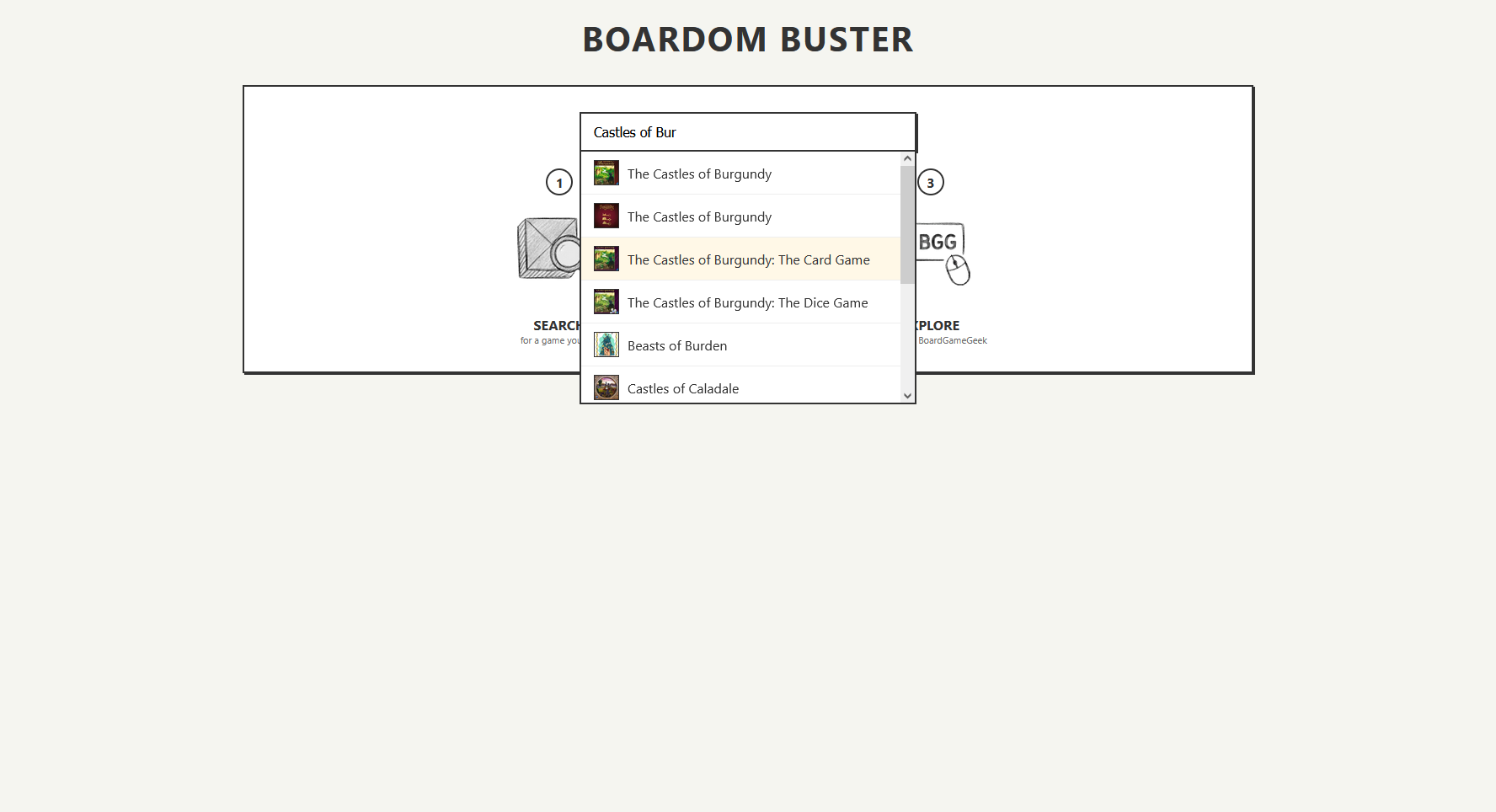
3. getting the recommendations
4. final recommendations
final remarks
finally, if you want to look deeper into the code itself you can find it here and any feedback is well welcomed!